




En Epsilon Technologies te ayudamos a guiar la operación de tu negocio con datos y AI
Integramos tus sistemas fragmentados, desarrollamos software a la medida que conecta toda tu operación y desplegamos inteligencia artificial que entiende el contexto completo de tu negocio.
Ingeniería de Datos Empresarial
La ingeniería de datos es la disciplina que transforma datos fragmentados en un ecosistema estructurado, unificado y gobernable. No es solo "conectar sistemas", sino diseñar la arquitectura completa que permite que los datos fluyan, se consoliden y generen valor.
Nuestro enfoque abarca tres pilares fundamentales:
01
Integración de Sistemas
Conectamos todas tus fuentes de datos en una arquitectura coherente: ERPs, CRMs, bases de datos, archivos Excel, APIs de aplicaciones SaaS, sistemas legacy, y dispositivos IoT o sensores en planta, prácticamente cualquier sistema que almacene información crítica.
Diseñamos pipelines automatizados que sincronizan información continuamente. Los datos fluyen de múltiples fuentes hacia un repositorio centralizado sin intervención manual.
02
Arquitectura de Datos Escalable
Diseñamos cómo se almacena, estructura y gobierna tu información de manera escalable. Implementamos data warehouses empresariales con tecnologías como Snowflake, BigQuery o Redshift y data lakes para datos no estructurados como documentos, imágenes o logs.
La arquitectura crece con tu negocio sin rediseños costosos, con replicación y backup automatizado para garantizar disponibilidad continua.
03
Calidad y Gobernanza de Datos
Integrar datos sin garantizar calidad no resuelve nada. Implementamos validaciones automatizadas que detectan inconsistencias, estandarizamos formatos cross-sistema, y aplicamos reglas de limpieza específicas a tu negocio.
Creamos tu single source of truth: cuando finanzas, operaciones y ventas consultan la misma métrica, todos obtienen exactamente el mismo número sobre los mismos datos fuente.
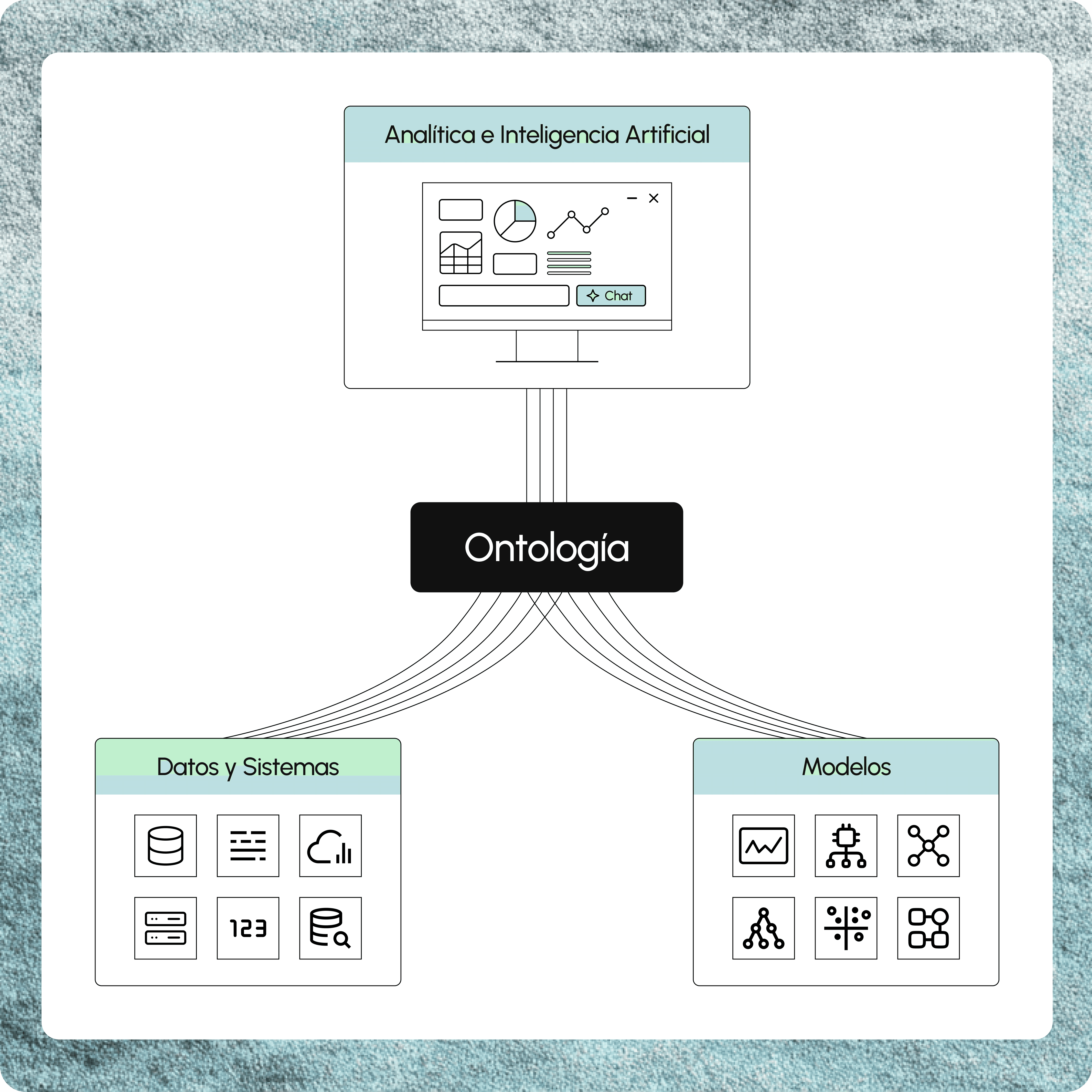
Construimos el sistema operativo de tu empresa
Más allá de mover y almacenar datos, modelamos el contexto semántico de tu negocio. Creamos una ontología empresarial que define entidades (Cliente, Producto, Orden, Proceso), sus características, y las relaciones entre ellas.
Este modelo semántico permite que diferentes sistemas "se entiendan" a pesar de usar terminología distinta. Esta capa semántica es indispensable para habilitar inteligencia artificial que comprenda el contexto completo de tu operación.
Del caos de datos a Inteligencia Operacional
Una infraestructura de ingeniería de datos bien diseñada desbloquea capacidades que antes eran imposibles:
Analítica unificada.
Dashboards y reportes que cruzan información de múltiples sistemas sin reconciliación manual.
Métricas calculadas sobre datos limpios y estandarizados.
Inteligencia artificial contextual.
Modelos de Machine Learning que consideran variables de toda tu operación y ofrecen predicciones más precisas.
IA generativa con acceso a contexto empresarial completo, puede responder preguntas complejas porque "conoce" tu negocio a través de la ontología.
Automatizaciones inteligentes.
Procesos que reaccionan a eventos cross-sistema. Cuando inventario cae bajo cierto nivel (ERP) y existe demanda proyectada alta (CRM), se genera orden de compra automáticamente.
Estas automatizaciones requieren datos unificados en tiempo real.
Digital Twin operacional
Una representación digital viva de tu empresa donde puedes simular escenarios. "¿Qué pasa si incrementamos producción 20% en planta Monterrey?"
El digital twin modela el impacto completo en tu operación. Solo es posible con una arquitectura de datos verdaderamente integrada.
Nuestro Proceso de Ingeniería de Datos
Transformar datos fragmentados en un ecosistema unificado requiere de una metodología probada.
Nuestro framework de ingeniería de datos abarca seis fases que van desde el diagnóstico inicial hasta la habilitación continua de casos de uso, con entregas de valor en cada etapa:
Diagnóstico del Ecosistema Actual
Mapeamos tu landscape tecnológico completo: sistemas fuente, volúmenes de datos, flujos de información actuales y pain points críticos.
Identificamos silos que bloquean decisiones y priorizamos casos de uso por impacto y complejidad. Definimos arquitectura objetivo con roadmap claro de implementación.
01
Diseño de Arquitectura Unificada
Diseñamos la arquitectura de datos que consolidará tu ecosistema.
Seleccionamos tecnologías de data warehouse, ETL y gobernanza según tus necesidades específicas. Definimos un modelo de datos con entidades, relaciones y esquemas optimizados para análisis.
02
Integración de Fuentes
Implementamos conectores a cada sistema fuente y construimos pipelines automatizados de sincronización.
Realizamos carga histórica (backfill) con validación rigurosa. Configuramos sincronización incremental o en tiempo real según requerimientos operacionales. Monitoreamos pipelines con alertas automáticas de fallas.
03
Implementación de Data Warehouse
Desplegamos infraestructura de almacenamiento y cargamos datos transformados en capas estructuradas (raw, staging, analytics).
Optimizamos performance con índices, particiones y clustering apropiados. Configuramos backup, replicación y disaster recovery para garantizar continuidad operacional.
04
Calidad y Gobernanza
Implementamos validaciones automatizadas en cada pipeline y configuramos data catalog con documentación completa.
Establecemos lineage tracking para trazabilidad de métricas a fuente. Definimos roles de acceso con permisos granulares y capacitamos usuarios en consulta de datos. Documentamos procesos operativos y troubleshooting.
05
Habilitación de Casos de Uso
Desplegamos aplicaciones sobre la infraestructura: dashboards ejecutivos con métricas unificadas, reportes automatizados que eliminan reconciliación manual, modelos predictivos de demanda o churn, y automatizaciones que reaccionan a eventos cross-sistema.
Iteramos agregando fuentes, métricas y casos de uso conforme el negocio evoluciona.
06
Ingeniería de Datos
por Industria

Manufactura
Las plantas operan con datos aislados en PLCs, SCADA, MES y ERP. Integramos estos sistemas en tiempo real y construimos data warehouse de manufactura con métricas unificadas de OEE, throughput y downtime, generando visibilidad completa desde piso de planta hasta dirección.
Explora Manufactura

Retail y E-commerce
Gestiona tienda física (POS), e-commerce, app móvil y fulfillment de forma ordenada. Integramos todos los canales con inventario sincronizado en tiempo real y analítica que unifica el comportamiento de compra online y offline en una vista completa del cliente.
Explora Retail y E-commerce


Logística
Los operadores logísticos manejan almacenes (WMS), transporte (TMS), última milla y facturación en sistemas separados. Integramos toda la cadena con track & trace en tiempo real que combina ubicación de flotilla, inventario y órdenes pendientes para optimizar rutas con datos históricos y actuales.
Explora Logística
Salud
Gestiona expedientes médicos (EHR/EMR), citas, facturación y laboratorios de manera ordenada. Unificamos toda la información en arquitectura segura donde médicos ven el historial completo del paciente en una sola vista, habilitando analítica que identifica patrones cross-pacientes.
Explora Salud


Servicios Profesionales
Opera con CRM, gestión de proyectos, time tracking y facturación conectados. Integramos estos sistemas para generar visibilidad unificada de pipeline comercial, proyectos activos, utilización de equipo y rentabilidad por cliente en tiempo real.
Explora Servicios Profesionales
Stack Tecnológico de Ingeniería de Datos
Seleccionamos tecnologías best-in-class según las necesidades específicas de tu proyecto.
